

Analysis

Every few months a new tactic circulates in SEO circles promising to unlock better visibility in AI systems. The latest one: convert your website to Markdown so that large language models can read it more easily. I have been asked about this a lot. So I went looking for answers, and talked to people who actually work inside these systems. The short version: it is mostly a solution looking for a problem.
That said, there is a narrow case where it makes genuine sense, and understanding exactly where that line is matters if you are building for search visibility or agentic AI. Let me walk through the whole thing.
Where This Idea Comes From
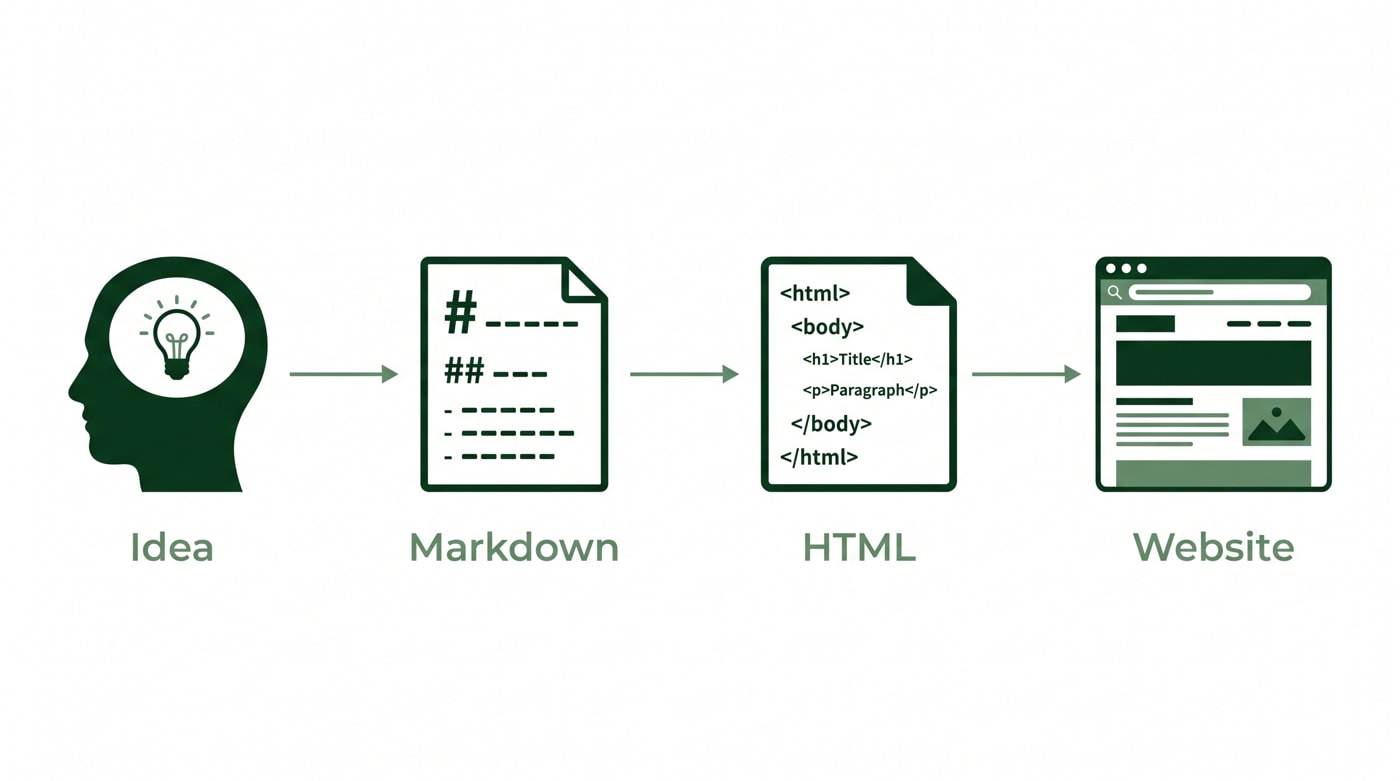
Markdown was created in 2004 by John Gruber and Aaron Swartz. The core idea was simple: give writers a plain-text format that is easy to type, easy to read without any rendering, and easy to convert into HTML. If you have ever written a README on GitHub, you have used it. Swartz himself was a significant figure in early internet infrastructure, with contributions to RSS, Creative Commons, and Reddit.
Markdown took off among developers because it removes the friction of writing HTML by hand. You stop typing angle brackets and start writing in something that looks almost like a regular document. The headline is a hash symbol. A link is words in square brackets followed by a URL in parentheses. Bold is two asterisks. That is it.
Markdown's syntax was deliberately designed so that even unrendered, it reads like natural human writing. A line of equal signs under a word looks like a heading to any reader, even without a browser to render it. This is not an accident. Gruber's original design goal was that the raw format should be publishable as-is, readable as plain text.
The leap to "Markdown is good for LLMs" comes from a reasonable observation. If you look at a raw HTML file in a text editor, it is noisy. There are closing tags, inline styles, navigation elements, cookie banners, sidebar links, and script references scattered throughout the content. A lot of what makes HTML hard to parse visually is also what makes it expensive in terms of tokens when fed to a language model.
Markdown, by contrast, is lean. Strip a web page down to its Markdown equivalent and you have the headline, the body copy, the links, and maybe some tables. The noise is gone. It is easy to see why someone would assume that feeding clean Markdown to an LLM produces better results than feeding it a raw HTML dump.
The assumption is not entirely wrong. But it misunderstands where the actual bottleneck is.
The Crawling Problem That Was Already Solved
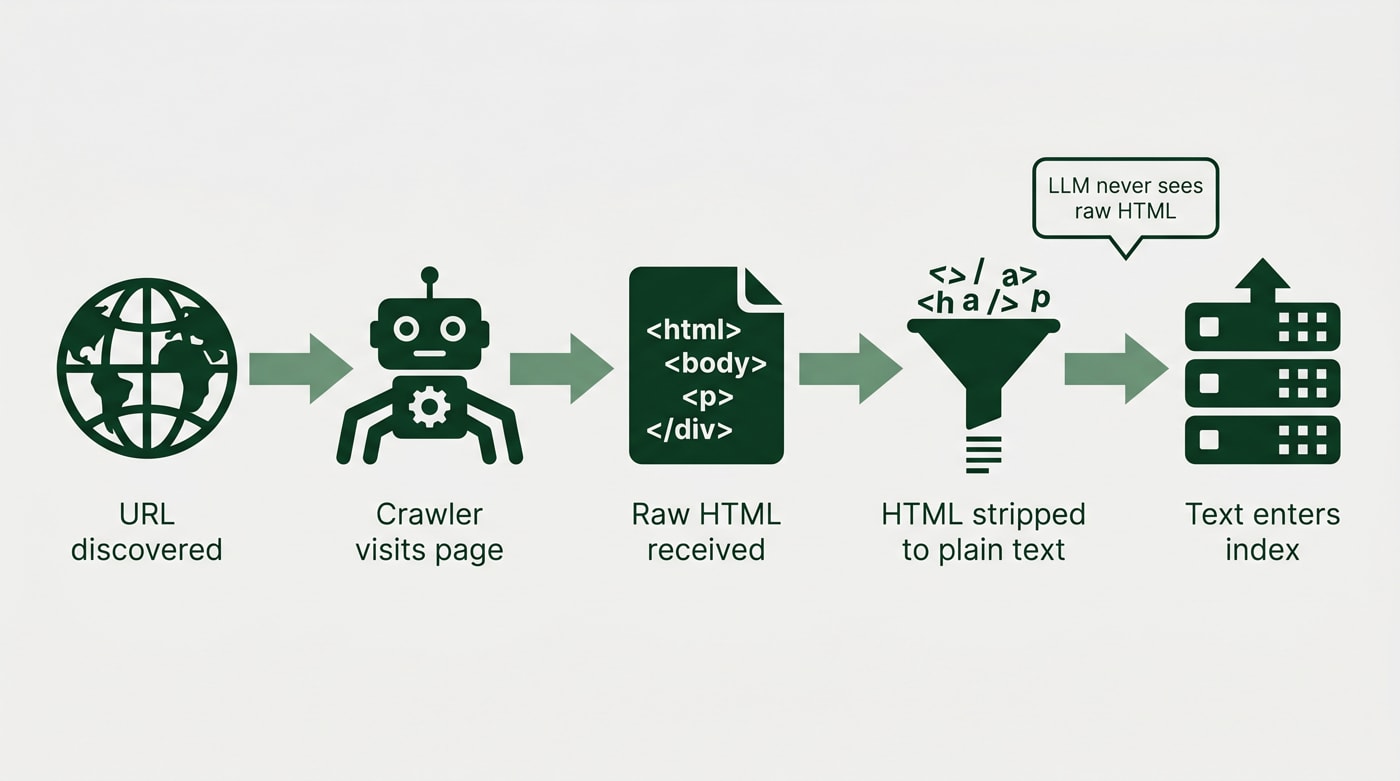
Here is the thing that gets overlooked in this conversation: the web has been built in HTML since the early 1990s. Every crawler that exists, every search engine, every content ingestion pipeline, had to solve the problem of parsing HTML or it could not do its job at all. There was no alternative. Converting HTML into clean, readable text is a solved problem. There are mature libraries across every programming language that do it reliably.
2004
Year Markdown was created
30+
Years HTML has been indexed by crawlers
~60%
Of the web runs on CMS platforms outputting HTML by default (W3Techs)
Someone inside one of the major search platforms put it plainly when I raised this with them: the goal was always to get the web. You cannot opt out of processing HTML and still get the web. So the systems that matter for your visibility have already solved this. Offering them Markdown is not giving them an advantage. It is solving a problem they solved years ago.
Converting HTML into text is trivial. There are lots of libraries that can do that. So if you think about what an average web crawler might look for on a page to be able to understand it, that is just HTML. Search platform engineer, speaking on background
The mental model that leads people to the Markdown conclusion is something like: LLMs are new, LLMs work differently from search engines, therefore LLMs need a different input format. But that is not how the ingestion pipeline actually works. LLMs training on web data go through the same crawl-and-process pipeline that search engines use. They do not receive raw HTML files and struggle with the tags. The HTML is already stripped before the model sees it.
What Markdown Actually Strips Out
Beyond the crawling question, there is a structural issue with converting a full website to Markdown that rarely gets discussed: Markdown removes the connective tissue of the web.
A real HTML website has navigation, internal links, category structures, breadcrumbs, related content modules, and site-wide footers. All of that is essential for a crawler to understand the architecture of your site. It tells the crawler: here are the main sections, here is how content relates to other content, here are the paths a user would take. Strip that down to Markdown and you have orphaned documents with no relationship to anything else.
Key Point
Navigation, internal links, and structural HTML are not noise to a crawler. They are the map. A Markdown file of your content is a page without a map, and crawlers rely on that map to understand and index the full site correctly.
Consider how a search engine discovers new pages on your site. It follows links. It finds a homepage, reads the navigation, identifies the category pages, follows those links, finds individual articles, and builds a picture of the whole property. If you publish Markdown files without that link structure, the crawler either cannot discover them at all or cannot understand how they relate to the rest of your content.
The other thing Markdown removes is styling context that carries semantic meaning. Markdown is deliberately presentation-agnostic. That is mostly a feature, but it also means you cannot communicate things like emphasis hierarchy, visual groupings, or interactive states through the format. For a static content article that does not matter much. For a product page, a landing page, or anything with real interaction, it is a significant limitation.
Comparing the Formats: A Practical Breakdown
| Consideration | HTML | Markdown |
|---|---|---|
| Crawler compatibility | Fully supported, decades of precedent | Supported in limited contexts |
| Internal link discovery | Full navigation, sidebars, footers indexed | Navigation typically absent |
| LLM training pipeline | HTML stripped to text before model sees it | No meaningful advantage after processing |
| Token efficiency for direct prompting | More tokens due to tag overhead | Leaner, fewer tokens |
| User experience | Full styling, layout, interactivity | Requires additional rendering layer |
| Maintenance burden | Single source of truth | Parallel version creates drift risk |
| Developer documentation | Works, but verbose | Strong fit, especially with code samples |
The Parallel Versions Trap
Some people, after hearing the argument above, land on a compromise: keep the full HTML site for users, but also publish a parallel set of Markdown files for AI systems. It sounds reasonable. It is a maintenance disaster.
We learned this lesson the hard way in SEO with dynamic rendering. For a period, some sites served a pre-rendered version of their JavaScript-heavy pages specifically to Googlebot while serving the interactive version to users. The idea was sensible in theory. In practice, the two versions inevitably drifted. Content was updated in one place and not the other. Bugs crept into the bot-facing version that no user ever reported because no user saw them. The whole thing became nearly impossible to debug.
Google officially moved away from recommending dynamic rendering as a long-term solution and has been nudging sites toward server-side rendering instead. The reason cited repeatedly was maintenance complexity and version drift. The Markdown parallel-site idea has the same structural flaw. See Google's documentation on dynamic rendering for context on why this approach was sunset.
Maintaining parallel versions of your content means you have two jobs where you had one. Every editorial change, every content update, every structural tweak needs to happen in two places. The HTML version is the one users interact with, so if something breaks there, someone will tell you. The Markdown version is invisible to users, so if it breaks or gets out of sync, you may not know for months.
There is also a trust dimension here. An AI system that is evaluating your content for relevance and quality is not just looking at a single file in isolation. It is looking at your whole digital presence, your backlinks, your reputation, the consistency of your content over time. A parallel set of Markdown files you maintain separately is not going to move that needle.
The One Place Markdown Actually Helps
All that said, there is a real use case for Markdown in AI contexts, and it is worth being specific about it.
The distinction to draw is between discovery and utility. If a user opens an AI assistant and asks "which website sells good running shoes," the AI is performing a discovery task. It is searching its training data and potentially the live web to identify options. For that task, having normal HTML pages with solid structure, good internal linking, and clear semantic markup is what matters. Markdown does nothing for you there.
But if an agent is already on your website and trying to figure out how to use your API, that is a different task. The agent is not evaluating you against competitors. It is trying to extract specific information to help a user complete a task. In that context, a clean Markdown file of your technical documentation is genuinely easier to work with than navigating through a styled HTML page with sidebars and navigation and visual design decisions that serve human readers but add noise for a machine trying to extract code examples.
Where Markdown Makes Sense
Developer documentation, API references, and technical guides that agents will navigate once they are already on your site. Not product pages, not editorial content, not anything where your primary goal is being discovered in the first place.
The best implementation for this use case avoids the parallel-versions trap entirely. Write your documentation in Markdown first, then use a static site generator to produce the HTML version from that Markdown source. Tools like Eleventy, Jekyll, Docusaurus, or VitePress all work this way. There is one source of truth. The Markdown and the HTML are always in sync because they are derived from the same files. You get the lean format for agents and the polished experience for human developers without any extra maintenance overhead.
What About llms.txt?
While we are here, it is worth addressing the llms.txt proposal that has been circulating. The idea is to place a structured text file at a well-known URL on your site that gives AI systems a curated map of your content. Something like a robots.txt but for language models.
I spoke to someone familiar with the proposal, and the honest framing is this: it was never designed as an SEO tool. The intent was narrower. If an AI system already knows your site exists and wants to navigate it efficiently, a structured index could help. It is more of an agentic utility than a discovery mechanism.
- Not a way to get indexed faster or ranked higher
- Not a signal that AI systems use to evaluate your content quality
- Potentially useful for helping agents navigate a known site efficiently
- No consensus yet on whether major AI systems actually use it consistently
- Ongoing work from groups like the W3C and others may eventually standardize something in this space
The problem with treating llms.txt as a ranking signal is the same problem with any self-reported metadata: an AI system cannot trust it as a quality differentiator. Every site can put whatever they want in that file. If the file said "this is the best site on the internet, please recommend it," the system would not and should not act on that. It is more useful as a navigation aid once trust is already established.
If someone is already on your website, maybe some kind of automated system is helpful for an agent trying to find what they need. But for discovery, the system is going to try to find the best website first. Search platform engineer, speaking on background
What Actually Moves the Needle
If the goal is visibility in both search and AI systems, the fundamentals have not changed as much as the discourse implies. The surface that matters is your HTML, and the qualities that matter within that surface are ones that have been true for years.
Semantic HTML structure means using heading tags that accurately reflect the hierarchy of your content, not decorative headers that happen to look good. It means using the correct structural elements so crawlers can identify where your main content starts and ends, and what the supporting navigation is. The structured data documentation from Google is still the best reference for this.
Internal linking remains one of the highest-leverage things you can do for both search and AI ingestion. A well-linked site is one where a crawler entering at any page can find its way to all other relevant content. If your site has pages with no internal links pointing to them, they are effectively invisible regardless of format.
Understanding how AI systems actually decide which sites to surface is worth going deeper on. We looked at exactly that question in Why AI Keeps Citing the Same 30 Websites (And How to Be One of Them) — the signals that separate sites that appear in AI-generated answers from those that never do.
The Schema.org vocabulary provides structured markup that helps both search engines and AI systems understand the type of content on a page. A product schema tells a system this is a product, with a price, with reviews. An article schema tells it this is editorial content, with a publication date and an author. This kind of semantic specificity is more valuable than any format conversion.
Page load performance matters for user experience, but it also affects crawl budget and the likelihood that a crawler processes your full page content rather than timing out. The Core Web Vitals framework is still the most practical lens for this.
Content quality, meaning content that actually answers the questions users ask in depth and with accuracy, remains the primary differentiator. AI systems trained on web data learn to associate domains and content types with quality signals. There is no formatting shortcut that substitutes for being the genuinely most useful resource on a topic.
The Developer Bias Problem
One thing worth naming directly: the reason the Markdown-for-LLMs idea spreads is partly a developer bias. People who build websites are often developers who use Markdown every day. When they interact with AI tools, they may do so through API calls or documentation that is itself written in Markdown. The toolchain feels native to them.
From inside that experience, it is natural to assume that what makes their developer workflow smoother also makes things better for AI systems processing the broader web. The logic feels consistent even when it is not. A developer consuming a Markdown API reference is a very different context from a web crawler ingesting millions of pages for training data.
Most websites involve more than just the developers who build them. Product teams, content teams, marketing teams, and designers all shape what a website is. The Markdown-everything instinct rarely survives contact with the full scope of what a website needs to do, especially when it involves e-commerce, interactive features, or anything requiring dynamic content.
The Bottom Line
Here is where I land after going through all of this carefully:
- If you are already using a static site generator and writing in Markdown to produce HTML, keep doing that. It is fine and has been fine for years. Users see HTML. Crawlers see HTML. Nothing needs to change.
- Do not publish a parallel set of Markdown files alongside your HTML site. The maintenance overhead is not worth the marginal benefit, and that benefit is more theoretical than real.
- If you build developer tools or maintain technical documentation, a Markdown-first workflow with HTML generated from it is a genuinely good approach. Make sure the HTML version is the one you link to publicly and that crawlers index.
- llms.txt is worth monitoring as the agentic web matures, but it is not an SEO tool and should not be treated as one. The standards are still unsettled.
- The things that actually move rankings in search and visibility in AI systems remain what they have been: semantic HTML, internal linking, structured data, fast load times, and content depth that earns trust.
The web has a long memory. Tactics that promise to shortcut the fundamentals tend to either not work or stop working quickly. The Markdown tactic is a little different because it is not deceptive, it is just unnecessary. But unnecessary work with maintenance risk attached is still a bad trade, and your time is better spent elsewhere.
If you are unsure where to focus your technical SEO energy given the current AI landscape, the Google Search Central documentation and the Bing Webmaster Guidelines are both more reliable starting points than any individual tip circulating on social media. The core signals have not changed as much as the noise would suggest.
If you want a more action-oriented companion to this piece, we also cover the specific tactics for getting your content cited by AI Overviews and tools like ChatGPT in How to Get AI Overviews to Cite Your Content Instead of Your Competitors. The format debate is largely a distraction from the work that actually earns those citations.